谷歌:性能不佳的微调模型不要扔,求一下平均权重就能提升性能
如何最大限度地提升模型精度?
最近,谷歌等机构发现:
性能不好的微调模型先不要扔,求一下平均权重!
就能在不增加推理时间以及内存开销的情况下,提高模型的准确性和鲁棒性。
比如,研究人员就使用该方法创造了 ImageNet1K 的新纪录:90.94%。

将它扩展到多个图像分类以及自然语言处理任务中,也能提高模型的分布外性能,并改善新下游任务的零样本性能。

而这个方法还有一个有趣的名字,叫Module soup——
是不是让人一下子就让人联想到了斐波那契汤的笑话?(昨天的汤+前天的汤=今天的新汤)

△ 知乎网友@hzwer,已授权
一共三种配方
回想一下在此之前,大家是如何给模型涨点的呢?
是不是先用各种超参数训练出多个微调模型,然后再挑出验证集上表现最好的那一个留下,其余丢掉?
由于神经网络是非线性的,在不同的 loss basin 中可能有许多解,因此 Module soup 这一采用保留所有微调模型的权重,对其进行平均的方法就可以提高性能,还是让人有点惊讶的。
不过,最近就已有研究发现,从相同的初始化配置中中独立优化的微调模型,位于相同的误差范围内 (lie in the same basin of the error landscape)。
之前也有研究证明,沿单个训练轨迹进行权重平均,可以提高随机初始化训练模型的性能。
作者正是从这些结论中受到启发。
Module soup 一共有三种“配方”(实现):统一汤(uniform soup)、贪婪汤(greedy soup)和学习汤(learned soup)。
其中greedy soup是最主要采用的实现,因为它的性能比直接均匀地平均所有权重更高。
具体来说,Greedy soup 通过顺序添加每个模型作为“汤”中的潜在成分构建而成,并且只有在保持验证集上的性能有所提高时才将相应模型保留在“汤”中。
排序按验证集精度的降序排列。

性能超越单个最佳微调模型
作者进行了全面的微调实验来确定 Module soup 的有效性。
首先是微调CLIP 和 ALIGN,这两个模型在图像-文本对上进行了对比损失预训练。
结果经过 module soup 操作后,两者在分布内和自然分布转移(distribution shifts)测试集上的表现都比最佳的单个微调模型性能更佳。

△ 左为 CLIP,右为 ALIGN
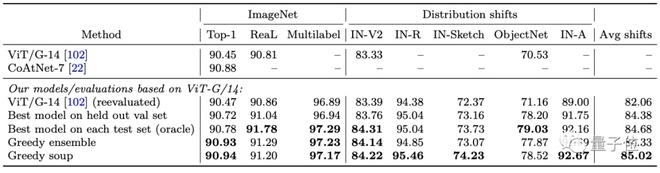
然后是在 JFT 数据集上预训练的ViT-G模型。
也就是它在 ImageNet1K 数据集实现了 90.94% 的精度,打破了此前 CoAtNet 保持的 90.88%,同时在推理阶段还减少了 25% 的 FLOPs。
在图像分类任务以外,作者在NLP领域也对 module soup 进行了验证。
下表是 BERT 和 T5 模型在 GLUE benchmark 的四个文本分类任务上的结果:

可以发现,虽然改进不如图像分类中的效果明显,但在多数任务下,greedy soup 都可以相较最好的单个模型提高性能。
当然,作者也指出,module soup 在适用性等方面存在局限,比如现在测试的都是在大型异构数据集上预先训练的模型,在这些模型之外,效果并不是非常明显。
最后,知乎网友@宫酱手艺人表示,其实这样的模型参数平均是一个经典 trick,transformer 原始论文就用了。

你发现了吗?
论文地址:
https://arxiv.org/abs/2203.0548
知乎@宫酱手艺人、@hzwer 回答(已授权):https://www.zhihu.com/question/521497951
来自: 网易科技