GAN如何异常检测?最新《生成式对抗网络异常检测》综述论文,概述异常检测的典型GAN模型

新智元报道
作者:专知
【新智元导读】异常检测是许多研究领域所面临的重要问题。生成对抗网络(GANs)和对抗训练过程最近被用来面对这一任务,产生了显著的结果。本文综述了主要的基于 GAN 的异常检测方法,并突出了它们的优缺点。
异常是数据中不符合正常行为的定义(Chandola et al., 2009) 的模式。
生成式对抗网络(GAN)和对抗训练框架(Goodfellow et al., 2014) 已成功应用于真实世界数据复杂和高维分布的建模。 这种 GAN 特性表明它们可以成功地用于异常检测,尽管它们的应用只是最近才被探索出来。
使用 GAN 进行异常检测的任务是使用对抗性训练过程建模正常行为,并测量异常评分来检测异常(Schlegl 等人,2017)。
据我们所知,所有基于 gan 的异常检测方法都是基于对抗性特征学习思想(Donahue et al., 2016),其中提出了 BiGAN 架构。
在最初的公式中,GAN 框架学习了一个将样本从任意潜在分布(噪声之前)映射到数据的生成器,以及一个试图区分真实样本和生成样本的鉴别器。
BiGAN 架构扩展了原始的模拟,增加了逆映射的学习,将数据映射回潜在的表示。 一个将输入数据映射到其潜在表示的学习函数和一个相反的函数(生成器)是使用 GAN 进行异常检测的基础。

https://arxiv.org/abs/1906.11632
在第 1 节,我们介绍了 GANs 框架,并简要介绍了其最具创新性的扩展,即条件 GAN 和 BiGAN,分别在第 1.2 节和第 1.3 节。第 2 节介绍了使用 GAN 进行异常检测的最新架构。在第 3 节中,我们对所有分析的架构进行了经验评估。最后,第四部分是结论和未来的研究方向.
GAN 异常检测
基于 GAN 的异常检测是一个新兴的研究领域。Schlegl et al.(2017),这里称为 AnoGAN,是第一个提出这一概念的人。
Zenati 等人(2018) 提出了一种基于 BIGAN 的方法,这里称为 EGBAD (Efficient GAN Based Anomaly Detection),其性能优于 AnoGAN 的执行时间。
最近,Akcay 等人(2018) 提出了一种基于 GAN + 自编码器的方法,其性能超过了 EGBAD。
AnoGAN
通过一个 GAN 的生成器G来学习正常数据的分布,测试时图像通过学习到的G找到它应该的正常图的样子,再通过对比来找到异常与否的情况。
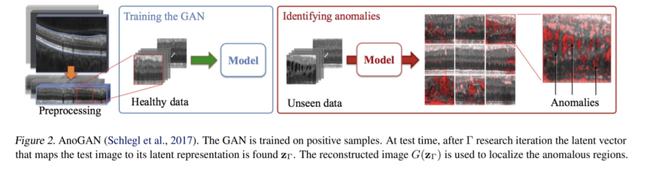
训练阶段:
对抗训练,从一个噪声向量Z通过几层反卷积搭建的生成器G学习生成正常数据图像。
测试阶段:
随机采样一个高斯噪声向量z,想要通过已经训练好的G生成一幅和测试图像x对应的正常图像G(z)。
G 的参数是固定的,它只能生成落在正常数据分布的图像。 但此时仍需进行训练,把z看成待更新的参数,通过比较G(z)和x的差异去更新 ,从而生成一个与x尽可能相似、理想对应的正常图像。
如果x是正常的图像,那么x和G(z)应该是一样的。
如果x异常,通过更新z,可以认为重建出了异常区域的理想的正常情况,这样两图一对比不仅仅可以认定异常情况,同时还可以找到异常区域。
EGBAD
高效基于 GAN 的异常检测(EGBAD) (Zenati et al., 2018) 将 BiGAN 架构引入到异常检测领域。
特别是,EGBAD 试图利用 Donahue 等人(2016) 和 Dumoulin 等人(2017) 的工作来解决 AnoGAN 的缺点,该工作允许学习一个编码器E,能够在对抗性训练期间将输入样本映射到它们的潜在表示
GANomaly
GANomaly 以编码器-解码器-编码器设计模型,通过对比编码得到的潜在变量和重构编码得到的潜在变量差异,从而判断是否为异常样本。
文章在无异常样本训练模型的情况下实现了异常检测,对于很多场景都有很强的实际应用意义。
GANomaly 模型对框架由三部分组成:
GE (x), GD (z) 统称为生成网络,可以看成是第一部分 。 这一部分由编码器 GE (x) 和解码器 GD (z) 构成,对于送入数据 x 经过编码器 GE (x) 得到潜在向量 z,z 经过解码器 GD (z) 得到 x 的重构数据 x̂ 。
模型的第二部分就是判别器 D , 对于原始图像 x 判为真,重构图像 x̂ 判为假,从而不断优化重构图像与原始图像的差距,理想情况下重构图像与原始图像无异。
模型的第三部分是对重构图像 x̂ 再做编码的编码器 E (x̂) 得到重构图像编码的潜在变量 ẑ。
在训练阶段,整个模型均是通过正常样本做训练。也就是编码器 GE (x),解码器 GD (z) 和重构编码器 E (x̂),都是适用于正常样本的。
当模型在测试阶段接受到一个异常样本,此时模型的编码器,解码器将不适用于异常样本,此时得到的编码后潜在变量 z 和重构编码器得到的潜在变量 ẑ 的差距是大的。
我们规定这个差距是一个分值, 通过设定阈值 ϕ,一旦 A (x)>ϕ 模型就认定送入的样本 x 是异常数据。


参考资料:
https://mp.weixin.qq.com/s/yOoDkTyZMmaFygt5MiGWtw
https://arxiv.org/abs/1906.11632
来自: www.163.com