Redis整合MySQL主从集群的示例代码
本文主要介绍了Redis整合MySQL主从集群的示例代码,文中通过示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
目录
1、用Docker搭建MySQL主从集群
1.1 拉取mysql镜像
1.2 创建配置文件夹
1.3 编写主服务器的配置文件信息
1.4 启动mysql主服务器的容器
1.5 观察主服务器状态
1.6 配置mysql从服务器
1.7 启动mysql从服务器
1.8 确认主从关系
2、准备数据
2.1 创建数据库
2.2 创建student数据表
2.3 向student表插入几条数据
3、用Java代码读写MySQL集群和Redis
3.1 引入redis和mysql依赖
3.2 代码整合
4、MySQL主从集群整合Redis主从集群
4.1 搭建Redis主从复制集群
4.2、代码整合
Redis作为承担缓存作用的数据库,一般会应用在高并发的场景里,而在这些高并发应用场景的数据库层面还会用到其他数据库的组件或集群以提升性能,比如用MySQL主从集群实现读写分离效果、用MyCAT组件实现分库分表的功能。另外,Redis本身会以集群的形式对外提供缓存服务。
1、用Docker搭建MySQL主从集群
这里用Docker容器搭建如下图所示的MySQL主从集群。

在主MySQL服务器里操作的动作会自动同步到从nysql服务器,比如在主服务器里发起的“建数据库”“通过insert语句插入数据”和“通过delete语句删除数据”的动作都会同步到从服务器,并且这些操作都会在从服务器上被执行。通过这种同步的动作能确保主从数据库间的数据一致性。
在项目里,一般是向“主服务器”里写数据,从“从服务器”里读数据,用这种“读写分离”的操作方式提升数据库性能。
具体搭建的步骤如下:
1.1 拉取mysql镜像
开启一个命令窗口,在其中运行docker pull mysql:latest,下载最新的mysql镜像。下载完成后,通过docker images mysql能看到如下图所示的镜像i信息。

1.2 创建配置文件夹
新建/root/redisconf/masterMySQL/conf和/root/redisconf/masterMySQL/data两个目录,在其中将会保存主mysql服务器的配置信息和数据。同时新建/root/redisconf/slaveMySQL/conf和/root/redisconf/slaveMySQL/data两个目录,在其中将会保存从MySQL服务器的配置信息和数据。当然,目录可自行更改。
1.3 编写主服务器的配置文件信息
在/root/redisconf/masterMySQL/conf目录里新建一个my.cnf文件,在其中编写针对主mysql服务器的配置信息,主mysql服务器在启动时会读取其中的配置,具体代码如下所示:
1 2 3 4 5 6 | [mysqld]pid-file =/var/run/mysqld/mysqld.pidsocket =/var/run/mysqld/mysqld.sockdatadir =/var/lib/mysqlserver-id =1log-bin=mysql-master-bin |
第二行到第四行给出了MYSQL运行时的参数,在第五行里定义了该服务器的id(这个id需要和之后编写的从MySQL服务器的server-id不一样,否则会出错),在第6行里制定了二进制文件的名字(为了搭建主从集群,建议加上这行配置)
1.4 启动mysql主服务器的容器
1 2 3 4 | docker run -itd --privileged=true -p 3306:3306 \--name myMasterMysql -e MYSQL_ROOT_PASSWORD=123456\-v /root/redisconf/masterMySQL/conf:/etc/mysql/conf.d\ -v /root/redisconf/masterMySQL/data:/var/lib/mysql mysql:latest |
-p3306:3306参数指定Docker容器里MySQL的工作端口3306映射到主机的3306端口
-itd参数指定该容器以后台交互模式的方式启动--name参数指定该容器的名字
通过-e MYSQL_ROOT_PASSWORD=123456参数指定该容器运行时的环境变量,具体到这个场景,配置以用户名root登录到MySQL服务器时所用到的密码123456.
两个-v参数指定外部主机和Docker容器间映射的目录。由于在第三步把MySQL启动时需要加载的my.cnf文件放在了/root/redisconf/masterMySQL/conf目录里,因此这里需要把/root/redisconf/masterMySQL/conf目录映射成容器内部MYSQL服务器的相关路径。
通过mysql:latest参数指定该容器是基于这个镜像生成的。
查看启动的容器:docker ps

由此能确认myMasterMysql启动成功。
查看该Docker容器的IP地址:docker inspect myMasterMysql

可以看到,这里是172.17.0.2,这也是主mysql服务器所在的Ip地址。
1.5 观察主服务器状态
运行docker exec -it myMasterMysql /bin/bash命令后进入该myMasterMysql容器的命令行窗口,再运行mysql -u root -p命令,进入MYSQL服务器的命令行窗口,在这个Mysql命令里,以-u参数指定用户名,随后需要输入密码(刚才设置的123456).
进入mysql服务器之后,再运行show master status命令观察主服务器的状态。
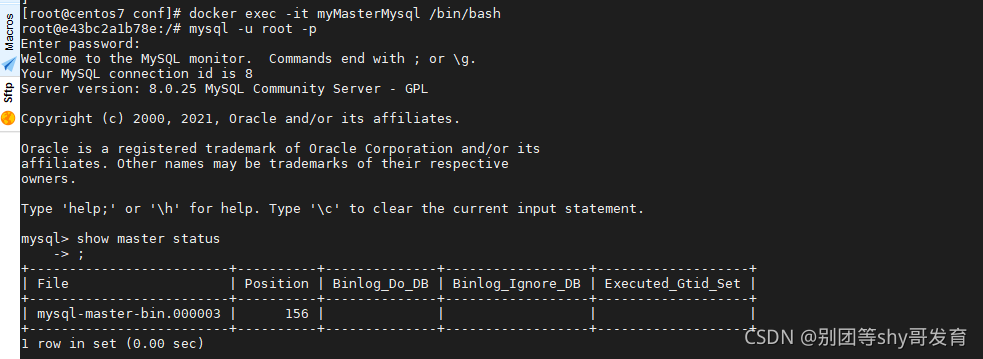
可以看到,主从集群同步所用到的日志文件是mysql-master-bin.000003,当前同步的位置是156,每次运行这个命令看到的结果未必相同,请记住这两个值,在设置从mysql服务器的主从同步关系时会用到。
1.6 配置mysql从服务器
在/root/redisconf/slaveMaster/conf目录里,新建一个名为my.cnf的文件,编写针对从MYSQL服务器的配置信息。同样的,从Mysql服务器在启动时也会读取其中的配置,具体代码如下所示。
1 2 3 4 5 6 | [mysqld]pid-file=/var/run/mysqld/mysqld.pidsocket=/var/run/mysqld/mysqld.sockdatadir=/var/lib/mysqlserver-id=2log-bin=mysql-slave-bin |
该配置文件和第三步创建的主服务器的配置文件很相似,只不过在第5行更改了server-id(这里的取值不能和主mysql服务器的一致)。在第6行也是设置二进制文件的名字
1.7 启动mysql从服务器
1 2 3 4 5 | docker run -itd --privileged=true -p 3316:3306\ --name mySlaveMysql -e MYSQL_ROOT_PASSWORD=123456\ -v /root/redisconf/slaveMySQL/conf:/etc/mysql/conf.d\ -v /root/redisconf/slaveMySQL/data:/var/lib/mysql\ mysql:latest |
这里在-p参数之后使用主机的3316端口映射Docker容器的3306端口,因为之前主mysql服务器的Docker容器已经映射到了3306端口,其他的参数和之前创建myMasterMysql容器时很相似,就不再重复了。
随后docker exec -it mySlaveMysql /bin/bash进入容器,进入后可以运行mysql -h 172.17.0.2 -u root -p命令,尝试在这个容器里连接主MySQL服务器。其中172.17.0.2是主服务器的地址。随后输入root用户的密码123456,即可确认连接。

确认链接后,通过exit命令退出指向myMasterMysql的连接,再通过mysql -h 127.0.0.1 -u root -p命令连接到本Docker容器包含的从MySQL服务器上。
1.8 确认主从关系
1 2 3 4 | change master to master_host='172.17.0.2',master_port=3306,\master_user='root',master_password='123456',\master_log_pos=156,\master_log_file='mysql-master-bin.000003'; |
本命令运行在mySlaveMysql容器中的从Mysql服务器里,通过master_host和master_port指定主服务器的ip地址和端口号,通过master_user和master_password设置了连接所用的用户名和密码。
注意master_logpos和master_log_file两个参数的值需要和第5步图中的结果一致。
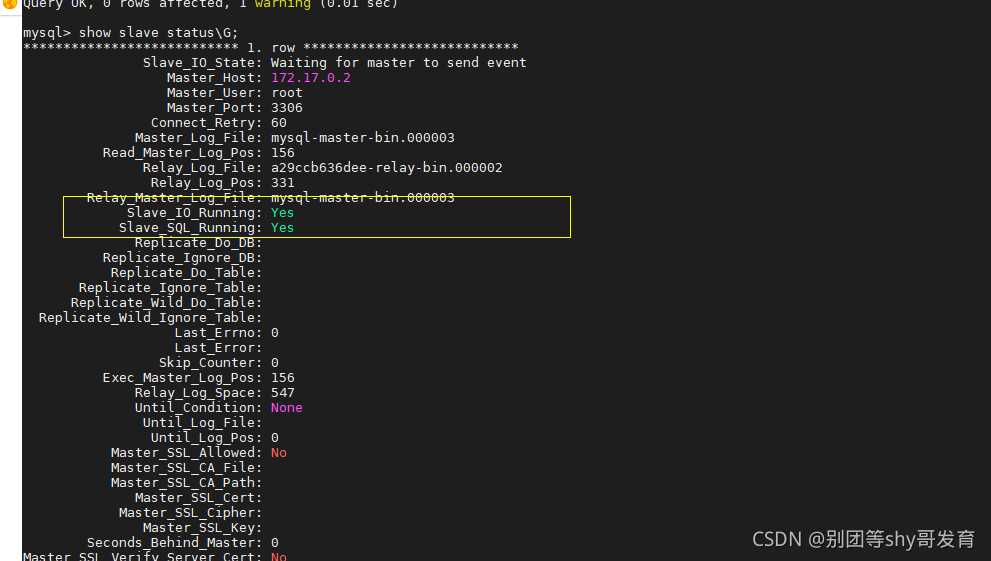
运行完成后,需要再运行start slave命令启动主从复制的动作。运行后可以通过show slave status\G;命令查看主从复制的状态,如果Slave_IO_Running和Slave_SQL_Running这两项都是Yes,并且没有其他异常,就说明配置主从复制成功。
此时如果再到主mysql服务器里运行create database redisDemo创建一个数据库,那么从库里虽然没有运行命令,但是也能看到redisDemo数据库,这说明已经成功地搭建了MySQL主从复制集群。其中,主库地IP地址和端口号是172.17.0.2:3306,从库是172.17.0.3:3306.
主库

从库

2、准备数据
由于已经成功地设置了主从复制模式,因此如下地建表和插入语句都只需要在主库里运行。
2.1 创建数据库
1 | create database redisDemo |
进入redisDemo数据库use redisDemo
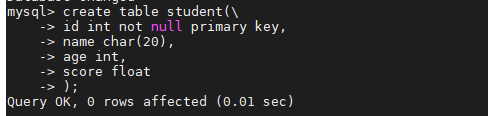
2.2 创建student数据表
1 2 3 4 5 6 | create table student( id int not null primary key, name char(20), age int, score float ); |
2.3 向student表插入几条数据
1 2 3 | insert into student(id,name,age,score) values(1,'Peter',18,100);insert into student(id,name,age,score) values(2,'Tom',17,98);insert into student(id,name,age,score) values(3,'John',17,99); |

从库里查看
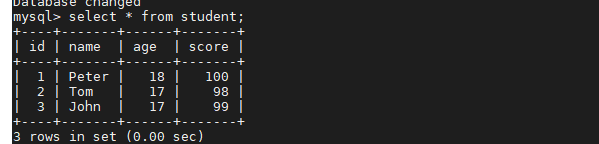
3、用Java代码读写MySQL集群和Redis
3.1 引入redis和mysql依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 | <!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.3.0</version> </dependency> <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.21</version> </dependency> |

Java应用程序是向主mySQL服务器写数据,这样写入地数据会自动同步到从mysql服务器上,而读数据时会先从Redis缓存里读,读不到时再到从mysql里读。以下用代码实现
3.2 代码整合
MySQLClusterDemo.java
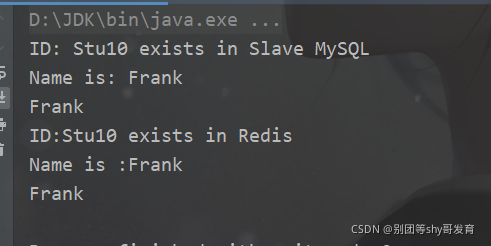
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 | import redis.clients.jedis.Jedis;import java.sql.*;public class MySQLClusterDemo { //创建操作Redis和数据库的对象 private Jedis jedis; private Connection masterConn; //连接主库的对象 private Connection slaveConn; //连接从库的对象 PreparedStatement masterPs=null; //对主库进行操作的对象 PreparedStatement slavePs=null; //对从库进行操作的对象 //初始化环境 private void init(){ //MYSQL的连接参数 String mySQLDriver="com.mysql.cj.jdbc.Driver"; String masterUrl="jdbc:mysql://192.168.159.33:3306/redisDemo?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true"; String slaveUrl="jdbc:mysql://192.168.159.33:3316/redisDemo?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true"; String user="root"; String pwd="123456"; try{ Class.forName(mySQLDriver); masterConn= DriverManager.getConnection(masterUrl,user,pwd); slaveConn= DriverManager.getConnection(slaveUrl,user,pwd); jedis=new Jedis("192.168.159.33",6379); }catch (SQLException e){ e.printStackTrace(); }catch (Exception e){ e.printStackTrace(); } } private void insertData(){ //是向主MySQL服务器插入数据 try{ masterPs=masterConn.prepareStatement("insert into student(id,name,age,score) values(10,'Frank',18,100)"); masterPs.executeUpdate(); }catch (SQLException e){ e.printStackTrace(); }catch (Exception e){ e.printStackTrace(); } } private String getNameByID(String id){ String key="Stu"+id; String name=""; //如果存在于Redis,就先从Redis里获取 if(jedis.exists(key)){ System.out.println("ID:"+key+" exists in Redis"); name=jedis.get(key); System.out.println("Name is :"+jedis.get(key)); return name; }else{ //如果没在Redis里,就到从MySQL里去读 try { slavePs=slaveConn.prepareStatement("select name from student where id=10"); ResultSet rs=slavePs.executeQuery(); if(rs.next()){ System.out.println("ID: "+key+" exists in Slave MySQL"); name=rs.getString("name"); System.out.println("Name is: "+name); //放入Redis缓存 jedis.set(key,name); } return name; }catch (SQLException e){ e.printStackTrace(); }catch (Exception e){ e.printStackTrace(); } } return name; } public static void main(String[] args) { MySQLClusterDemo tool=new MySQLClusterDemo(); tool.init(); tool.insertData(); //场景1 没有从Redis中找到,就到从MySQL服务器中去读 System.out.println(tool.getNameByID("10")); //场景2,当前ID=10的数据已存在于Redis,所有直接读缓存 System.out.println(tool.getNameByID("10")); }} |
运行结果
4、MySQL主从集群整合Redis主从集群
上面的mysql主从集群至整合了一个Redis主机,在这种模式里如果Redis服务器失效了,那么整个缓存可能都会失效。可以在次基础上引入Redis主从复制集群,以提升缓存的可用性以及性能,改进后的框架图如下所示。

应用程序同样是向主mysql服务器里写数据,这些数据同步到从mysql数据库里。
应用程序先到“从Redis服务器”里读取缓存,如果找不到,就再到从mysql数据库里去读。
如果从“从mysql数据库”里读到数据,那么需要写入“主Redis”,而根据Redis集群的主从复制机制,该数据会被写入“从Redis服务器”。这种针对Redis集群的读写分离机制能提升读写缓存的性能。
4.1 搭建Redis主从复制集群
4.1.1 创建redis-master容器
1 | docker run -itd --name redis-master -p 6379:6379 redis:latest |

4.1.2 创建resis-slave容器
1 | docker run -itd --name redis-slave -p 6380:6379 redis:latest |

4.1.3 查看redis服务器的ip
1 | docker inspect redis-master |

可以看到,redis-master的ip地址为172.17.0.4
4.1.4 主从配置
在redis-slave容器的窗口里,通过docker exec -it redis-slave /bin/bash命令进入容器的命令行窗口。运行如下的slaveof命令,指定当前服务器为从服务器,该命令的格式是slaveof IP地址 端口号,这里指向172.17.0.2:6379所在的主服务器。
1 | slaveof 172.17.0.4 6379 |

运行完该命令后,在redis-slave客户端里再次运行info replication

可以看到,该redis-slave已经成为从服务器,从属于172.17.0.2:6379所在的Redis服务器。
4.2、代码整合
MySQLClusterImprovedDemo.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 | import redis.clients.jedis.Jedis;import java.sql.*;public class MySQLClusterImprovedDemo { //创建操作Redis和数据库的对象 private Jedis masterJedis; //指向主Redis服务器 private Jedis slaveJedis; //指向从Redis服务器 private Connection masterConn; //连接主库的对象 private Connection slaveConn; //连接从库的对象 PreparedStatement masterPs=null; //对主库进行操作的对象 PreparedStatement slavePs=null; //对从库进行操作的对象 private void init(){ //MYSQL的连接参数 String mySQLDriver="com.mysql.cj.jdbc.Driver"; String masterUrl="jdbc:mysql://192.168.159.33:3306/redisDemo?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true"; String slaveUrl="jdbc:mysql://192.168.159.33:3316/redisDemo?useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true"; String user="root"; String pwd="123456"; try{ Class.forName(mySQLDriver); masterConn= DriverManager.getConnection(masterUrl,user,pwd); slaveConn= DriverManager.getConnection(slaveUrl,user,pwd); masterJedis=new Jedis("192.168.159.33",6379); slaveJedis=new Jedis("192.168.159.33",6380); }catch (SQLException e){ e.printStackTrace(); }catch (Exception e){ e.printStackTrace(); } } private void insertData(){ //是向主MySQL服务器插入数据 try{ masterPs=masterConn.prepareStatement("insert into student(id,name,age,score) values(10,'Frank',18,100)"); masterPs.executeUpdate(); }catch (SQLException e){ e.printStackTrace(); }catch (Exception e){ e.printStackTrace(); } } private String getNameByID(String id){ String key="Stu"+id; String name=""; //如果存在于Redis,就先从Redis里获取 if(slaveJedis.exists(key)){ //到从Redis服务器去找 System.out.println("ID: "+key+" exists in Redis."); name=slaveJedis.get(key);//找到后到从Redis里读 System.out.println("Name is: "+slaveJedis.get(key)); return name; }else{ //没在Redis,就到从MySQL去读 try{ slavePs=slaveConn.prepareStatement("select name from student where id=10"); ResultSet rs=slavePs.executeQuery(); if(rs.next()) { System.out.println("ID: "+key+" exists in Slave MySQL"); name=rs.getString("name"); System.out.println("Name is: "+name); //放入主Redis缓存 masterJedis.set(key,name); } return name; }catch (SQLException e){ e.printStackTrace(); }catch (Exception e){ e.printStackTrace(); } } return name; } public static void main(String[] args) { MySQLClusterImprovedDemo tool=new MySQLClusterImprovedDemo(); tool.init(); tool.insertData(); //场景1 在主Redis中没有读到,则到从MySQL服务器中读 System.out.println(tool.getNameByID("10")); //场景2 当前ID=10已经存在于Redis,所以直接读缓存 System.out.println(tool.getNameByID("10")); }} |
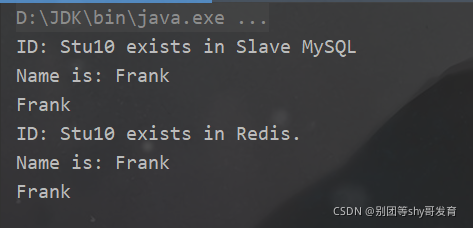
为了突出重点,这里我并没有设置“缓存失效时间”和“防止缓存穿透”等方面的实施代码,但是这些要点同样重要。
到此这篇关于Redis整合MySQL主从集群的示例代码的文章就介绍到这了
原文链接:https://blog.csdn.net/qq_43753724/article/details/120489532